As AI/ML workloads explode, particularly large language models and generative AI applications, organizations face an unprecedented demand for computational power.
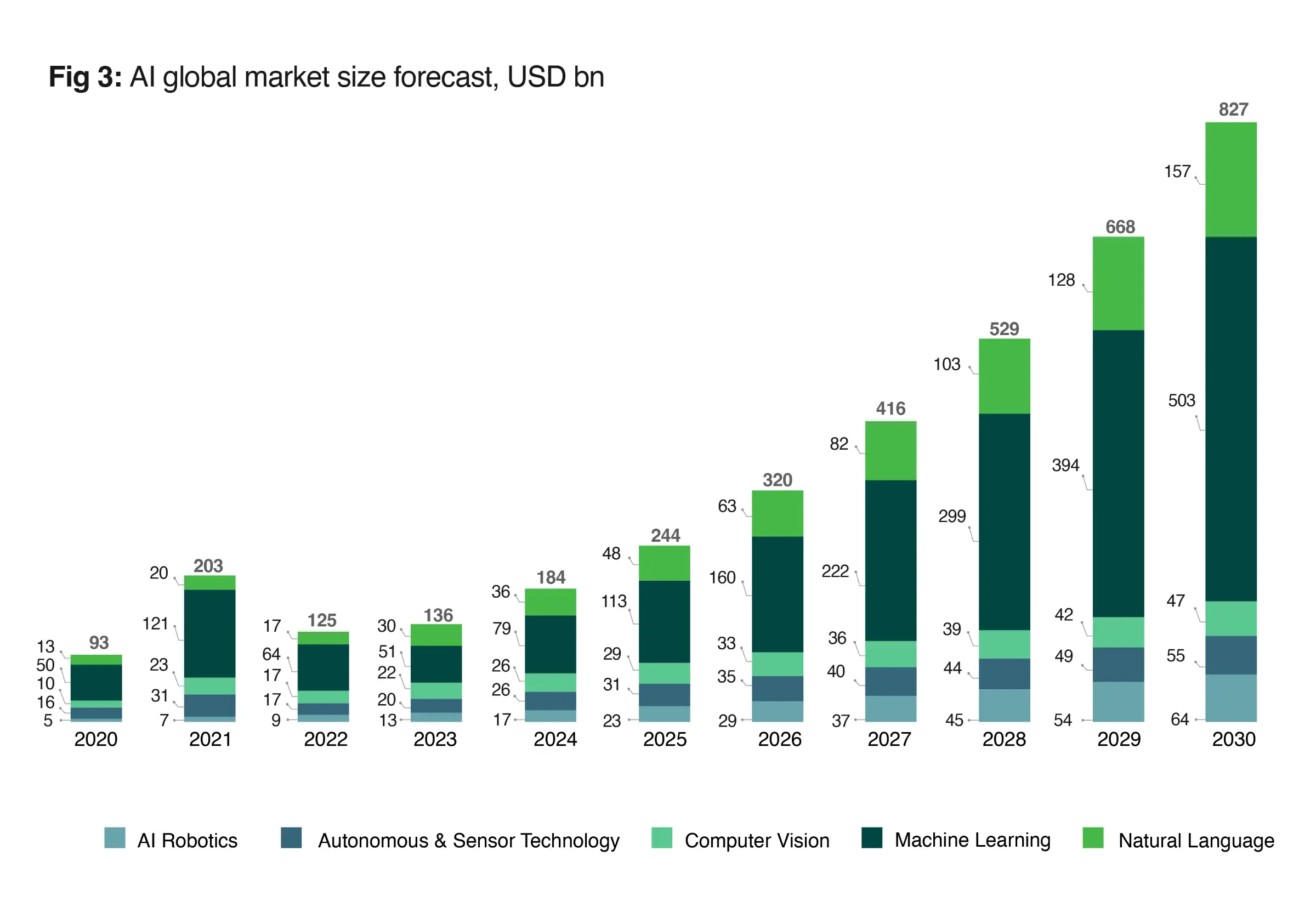
The global GPU-as-a-Service market, addressable by telecommunications companies alone, is projected to reach $35-70 billion by 2030, indicating a massive enterprise appetite for scalable GPU infrastructure.
Yet a critical gap persists.
Access to secure, cost-effective, and truly scalable GPU infrastructure remains very limited for most enterprises. Traditional cloud solutions often fall short of meeting specialized AI-ready cloud requirements. And the on-premises deployments demand prohibitive capital investments.
This is where GPU-as-a-Service and GPU private cloud solutions come in. These innovative GPU cloud hosting models are redefining enterprise AI infrastructure, delivering the computational muscle organizations need to compete in the AI-first economy.
Dive in to know all about these models!
Why GPUs Are Now Mission-Critical
The shift toward GPU-accelerated computing represents more than a technological evolution; it’s an economic imperative driving unprecedented infrastructure transformation.
Modern AI workloads, from deep learning and generative AI to real-time simulation and video analytics, demand massive parallel processing capabilities that traditional CPU architectures simply cannot deliver.
This computational reality has created a perfect storm where legacy infrastructure becomes the primary bottleneck constraining enterprise AI initiatives, leading to prolonged training cycles, cost overruns, and delayed product launches that can cripple competitive positioning in rapidly evolving markets.
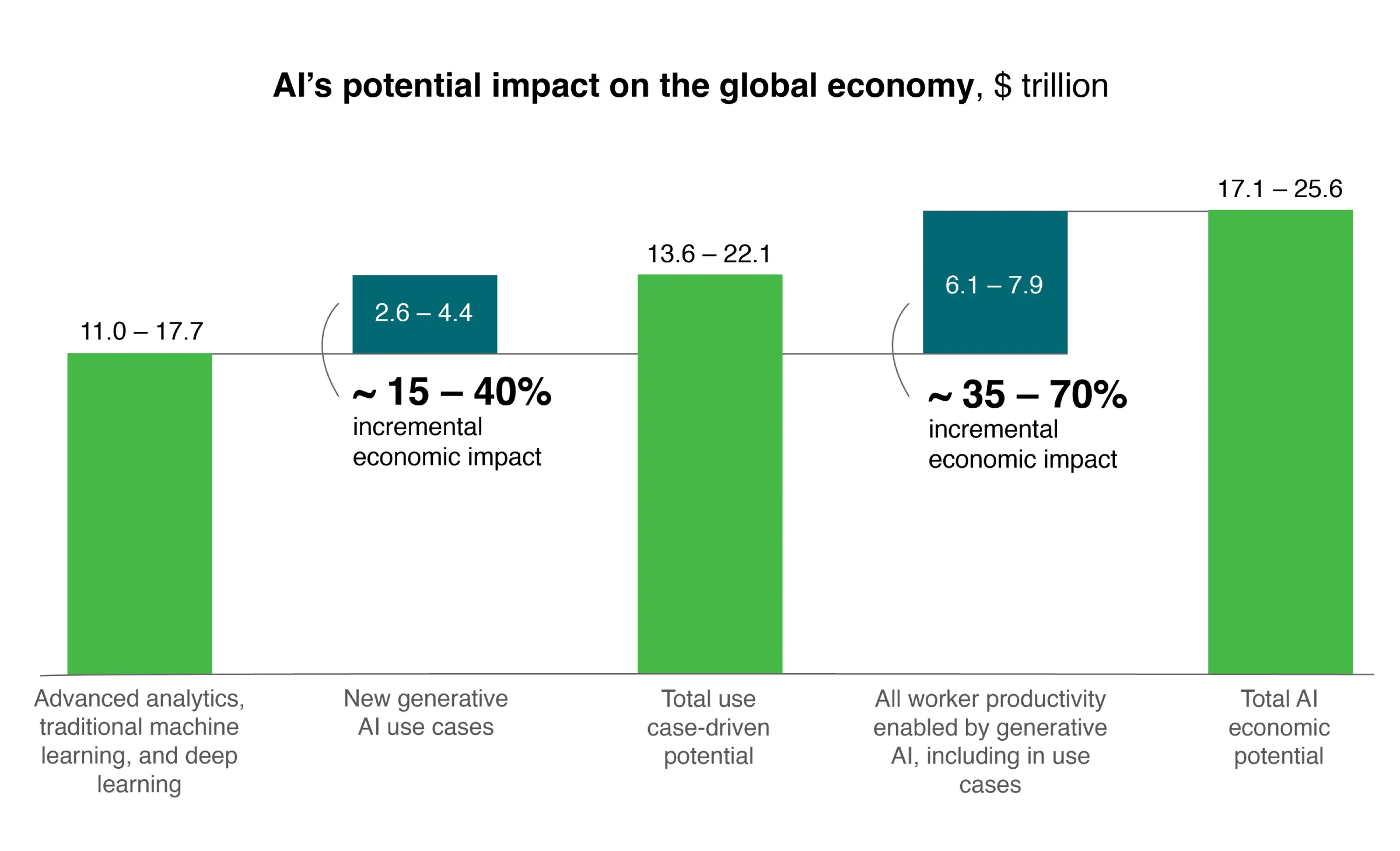
$4.4T Profit Potential
McKinsey research reveals that artificial intelligence could unlock up to $4.4 trillion in annual corporate value creation, but this extraordinary economic potential remains locked behind adequate GPU infrastructure investments. Organizations lacking sufficient compute capacity risk being spectators rather than participants in the AI-driven transformation reshaping global markets.
$6.7T Infrastructure Gap
The infrastructure investment required to support this AI revolution is staggering, with McKinsey projecting that data centers worldwide will need $6.7 trillion in capital investments by 2030 to meet surging compute demand. GPU capacity represents the most critical component of this infrastructure buildout, positioning GPU-as-a-Service as essential for organizations seeking scalable access without prohibitive upfront costs.
100% GPU Accelerator Adoption Surge
Gartner forecasts that GPU accelerator adoption will double within two to five years, escalating from the current 20-50% enterprise adoption rate to mainstream deployment across industries. This acceleration reflects growing recognition that GPU-accelerated computing delivers exceptional performance gains for parallel compute-intensive workloads, particularly in deep neural network training and real-time inference applications.
91% GPU Capacity Expansion
Enterprise commitment to GPU infrastructure is unmistakable, with Gartner reporting that 91% of organizations plan to increase their GPU capacity by an average of 23% within the next twelve months. This near-universal expansion underscores how GPU private cloud and GPU-as-a-Service solutions have become strategic necessities rather than optional enhancements for AI-ready cloud infrastructure.
What is GPU-as-a-Service (GPU-aaS)?
GPU-as-a-Service delivers on-demand access to powerful GPU clusters through cloud infrastructure, eliminating the complexity and capital requirements of hardware ownership. This model transforms enterprise AI infrastructure from a capital expenditure burden into an operational flexibility advantage.
Ideal Applications
- Foundation Model Training: Scale training workloads for large language models and custom AI applications without infrastructure constraints
- Inference-Heavy Workloads: Deploy real-time AI services with guaranteed performance and automatic scaling capabilities
- Pilot-to-Scale Experimentation: Rapidly prototype and iterate AI initiatives without committing to long-term hardware investments
GPU-aaS at CtrlS provides instant access to cutting-edge hardware, offering zero vendor lock-in and up to 50% cost advantages over traditional GPU cloud hosting solutions.
What is a GPU Private Cloud? And When Do You Need It?
GPU private cloud represents dedicated, isolated GPU infrastructure exclusively managed for your enterprise, fundamentally different from shared public cloud environments. This enterprise AI infrastructure model provides organizations with complete control over their computational resources while maintaining the scalability benefits of cloud architecture. Unlike multi-tenant public clouds where resources are shared across multiple users, GPU private cloud ensures your workloads operate in a dedicated environment with guaranteed performance, security, and compliance alignment.
Best Use Cases
- Regulated Industries: BFSI, healthcare, and defense sectors requiring strict compliance with data protection regulations and industry standards
- High-Performance Training: Enterprises running continuous AI model training that demands consistent, predictable GPU performance without resource contention
- Proprietary Data Processing: Organizations handling sensitive intellectual property or competitive datasets requiring isolated processing environments
- Data Sovereignty: Companies needing to maintain data residency within specific geographical boundaries or jurisdictions
- Mission-Critical Inference: Real-time AI applications where performance degradation could impact business operations or customer experience
- Large-Scale Deployments: Enterprises scaling AI initiatives across multiple departments requiring centralized GPU resource management
Key Benefits
- Zero Noisy Neighbors: Guaranteed resource allocation without performance interference from other tenants or workloads
- Predictable Cost Structure: Fixed pricing models eliminating surprise egress charges and API usage fees common in public cloud environments
- Cost Optimization: Up to 75% cost reduction through right-sizing infrastructure to match actual workload requirements
- Enhanced Security: Zero-trust security architecture with dedicated network isolation and customizable security protocols
- Data Residency Control: Complete governance over data location and movement, ensuring compliance with regional regulations
- Custom Configuration: Tailored GPU configurations optimized for specific AI-ready cloud workloads and enterprise requirements
GPU-aaS vs GPU Private Cloud: How to Choose
The choice between GPU-as-a-Service and GPU private cloud fundamentally depends on your enterprise’s specific AI infrastructure requirements, compliance obligations, and operational priorities.
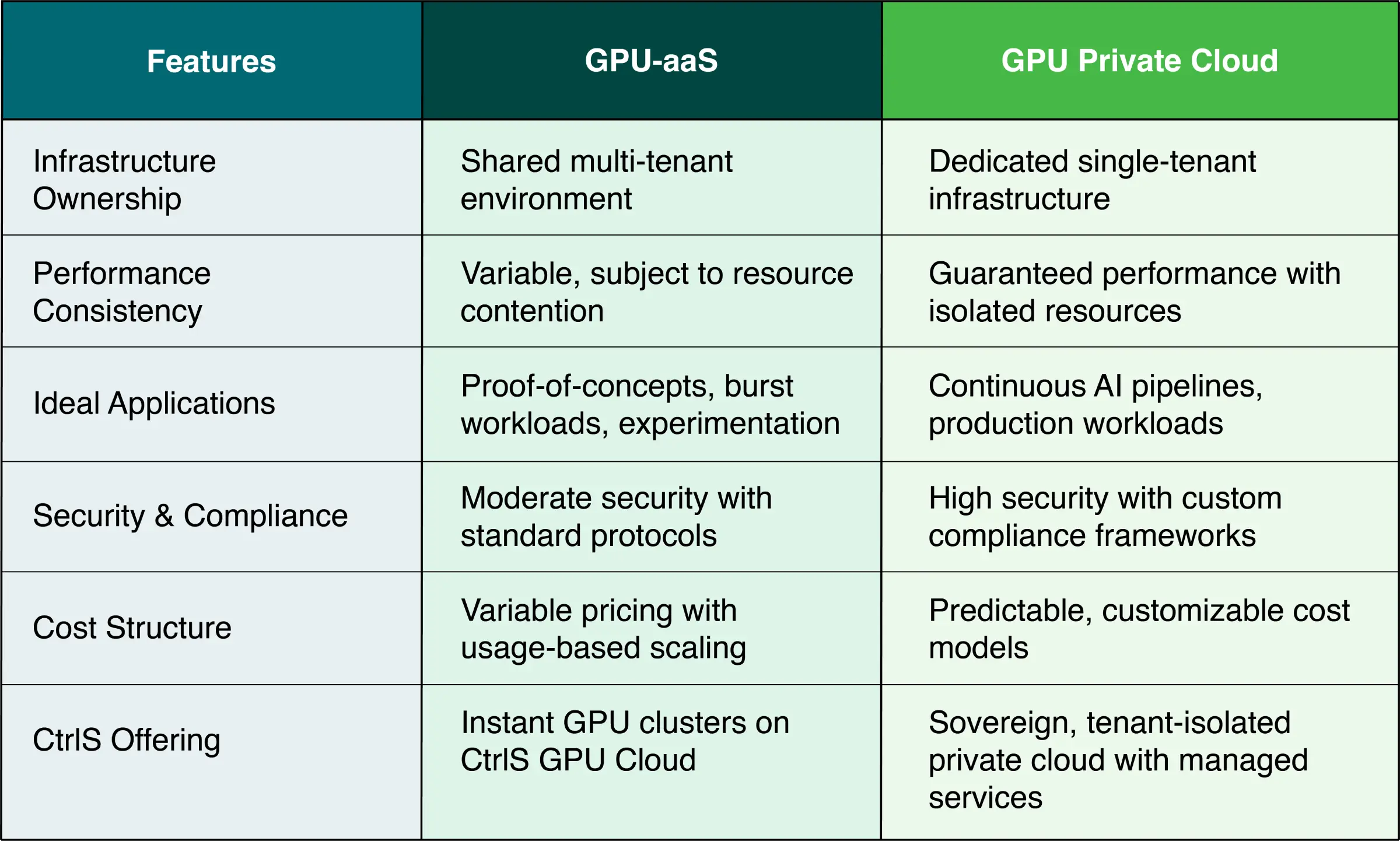
How to Choose: Real-World Examples
Choose GPU-aaS when: A fintech startup needs to rapidly prototype fraud detection models across multiple datasets before committing to production infrastructure. Their data science team requires flexible access to different GPU types for experimentation without long-term commitments.
Choose GPU Private Cloud when: A pharmaceutical company developing proprietary drug discovery AI models requires consistent performance for 24/7 molecular simulation workloads, strict data sovereignty compliance, and integration with existing enterprise security frameworks. Their continuous training pipelines demand predictable performance without external interference.
CtrlS GPU Stack: Not Just Infra, A Full AI Ecosystem
CtrlS delivers comprehensive enterprise AI infrastructure that extends far beyond basic GPU access, providing a complete ecosystem designed for mission-critical AI workloads across regulated industries.
Enterprise-Grade Infrastructure
CtrlS deploys high-performance GPU clusters featuring cutting-edge 400G/800G networking fabrics that deliver 40-100+ Gbps throughput with ultra-low latency. The infrastructure leverages blazing-fast storage architecture with 100 GBps throughput, tiered SSD/NVMe backends, and metadata optimization specifically engineered for AI-scale checkpointing and large model training workflows.
Unified AI Platform
The comprehensive ML portal provides unified GPU management through ACP (AI Control Plane), integrating Kubernetes and SLURM orchestration for seamless container management. This AI lifecycle management platform includes RAG pipeline orchestration, real-time analytics, flexible scaling capabilities, and direct integration with Jupyter Notebooks and SSH command-line access.
Comprehensive AI Services
CtrlS offers end-to-end MLOps services including LangChain support for complex AI application development, professional model tuning and porting services, and seamless vector database integration. These managed services span the complete AI lifecycle from infrastructure provisioning to autonomous agent deployment.
Zero-Trust Security Architecture
The platform implements enterprise-grade security with complete tenant isolation using dedicated VLANs, VRFs, and virtual firewalls. Data protection includes AES-256 encryption for data-at-rest and TLS 1.3 for data-in-transit, complemented by KMS integration for automated key rotation and secure BMC API exposure.
Industry-Specific Solutions
CtrlS serves mission-critical AI workloads across BFSI (fraud detection, risk analytics), Healthcare (medical imaging, drug discovery), GovTech (intelligence analytics, smart city infrastructure), Pharma (genomic sequencing), Manufacturing (digital twin simulation), and Aerospace (autonomous systems) sectors with tailored compliance frameworks.
Key Benefits You Can Expect of GPU-aaS and GPU Private Cloud
Organizations leveraging CtrlS GPU-as-a-Service and GPU private cloud solutions experience transformative improvements in AI deployment velocity, operational efficiency, and cost optimization. These enterprise AI infrastructure benefits extend beyond technical capabilities to deliver measurable business outcomes that directly impact competitive positioning, regulatory compliance, and bottom-line performance across diverse industry verticals.
- Faster Go-to-Market: Accelerate AI product development cycles by eliminating infrastructure provisioning delays, enabling immediate access to cutting-edge GPU resources for rapid prototyping, testing, and production deployment
- No GPU Waste: Optimize resource utilization through right-sizing capabilities and on-demand scaling, eliminating the inefficiencies of over-provisioned hardware and underutilized capacity
- Stay Compliant: Maintain regulatory adherence through Zero Trust security architecture and comprehensive data sovereignty controls, ensuring sensitive workloads meet industry-specific compliance requirements
- Save Up to 50%: Achieve significant cost reductions compared to hyperscaler public GPU clouds through transparent pricing models, eliminated egress fees, and customizable resource allocation
- Free Up ML Teams: Enable data science teams to focus on model innovation rather than infrastructure management, with comprehensive managed services handling operational complexities
- Guaranteed Performance: Ensure consistent, predictable AI workload performance through dedicated resources and tenant isolation, eliminating noisy neighbor effects
- Enterprise Security: Protect intellectual property and sensitive data with advanced encryption, network isolation, and comprehensive security monitoring across all AI-ready cloud environments
Future-Proofing with CtrlS GPU Private Cloud
The enterprise AI landscape evolves at breakneck speed, demanding infrastructure solutions that adapt seamlessly to changing technological requirements and business objectives.
CtrlS GPU private cloud architecture delivers this essential flexibility through its multi-cloud-ready design, allowing organizations to avoid vendor lock-in while maintaining consistent performance across hybrid environments. This strategic approach ensures that enterprises can leverage the best capabilities from multiple cloud providers without compromising operational efficiency or security protocols.
CtrlS unifies GPU-as-a-Service and GPU private cloud capabilities through a single, intuitive control plane that simplifies complex multi-environment management. This unified approach enables seamless workload migration between deployment models as business needs evolve, whether scaling from experimental workloads to production environments or adapting to changing compliance requirements.
The platform’s customizable cluster configurations and storage architectures ensure that infrastructure can be precisely tailored to specific AI workload demands, optimizing both performance and cost efficiency.
The managed AI stack incorporates built-in guardrails that automatically enforce security policies, resource governance, and compliance standards across all enterprise AI infrastructure deployments. These intelligent safeguards reduce operational overhead while ensuring that AI initiatives remain aligned with corporate governance frameworks, enabling organizations to innovate confidently within established risk parameters and regulatory boundaries.
Conclusion: Own Your Stack, Accelerate Your AI
In the AI age, infrastructure is your moat. Your competitive advantage hinges not just on algorithms, but on the foundation that powers them. Whether you’re training large language models or scaling enterprise AI initiatives, your GPU strategy fundamentally determines both your innovation pace and market power.
CtrlS GPU Private Cloud and GPU-aaS solutions empower organizations to innovate securely, operate at scale, and maintain complete control over their AI destiny.
Ready to accelerate your AI journey? Contact us to discuss building your comprehensive GPU roadmap or request a complimentary infrastructure assessment to identify your optimization opportunities.

Manzar Saiyed, Vice President - Service Delivery, CtrlS Datacenters
With over 15 years of rich experience in project and program management, Manzar has been instrumental in planning and executing mid to large size complex initiatives across different technologies and geographies. At CtrlS, he is responsible for solutioning and bidding for large system integration projects across emerging markets.
 marketing@ctrls.in
marketing@ctrls.in