The first cloud invoice did not raise any red flags. It reflected a predictable month-on-month increase, well within planned budgets. Over the next few billing cycles, however, infrastructure costs began to trend upward in a way that could not be explained by new model training or expanded AI initiatives. The models were already in production. The product roadmap had not materially changed. Yet, cloud spending continued to rise.
This is the new reality of enterprise GenAI. The real cost pressure does not originate in the training phase. It accumulates in production, through the continuous serving of models to users. Inference, not training, is fast becoming the dominant driver of AI infrastructure economics. For CIOs and CTOs, this marks a structural shift in how GenAI must be planned, governed, and financially engineered.
This shift is now visible in market data. Gartner’s October 2025 forecast shows spending on inference-led AI applications nearly doubling from USD 9.2 billion in 2025 to USD 20.6 billion in 2026, with 55% of AI-optimised IaaS capacity in 2026 dedicated to serving workloads.
The implication is simple but uncomfortable. If inference is architected as an afterthought, GenAI will scale in usage but not in financial discipline.
When inference overtakes training in enterprise economics
The early GenAI narrative celebrated the spectacle of training large models with massive GPU clusters and multi week runs. In reality, most enterprises rarely train foundation models. They fine tune or consume them. What runs continuously in production is inference.
Every interaction with a virtual assistant, every internal query to a knowledge bot, every document summarised is an inference event. Unlike training, which is episodic, inference is perpetual. It operates across business hours, peaks, and quiet periods, embedding itself into everyday workflows and customer experiences.
Over time, this persistence reshapes the cost curve. Small per request costs compound into a significant recurring infrastructure bill. Across the lifecycle of a mature GenAI application, inference often becomes the dominant driver of compute spend. In effect, inference starts to look less like a project cost and more like a utility expense, shaped by early architectural choices.
Why GenAI Inference Costs Rise Faster Than Leaders Expect
At first glance, inference appears inexpensive. A single query costs little. A single response is fast. The shift happens when GenAI moves from experimentation into everyday use. What begins as a pilot becomes embedded across workflows and customer journeys. Costs rarely spike overnight. They compound quietly with adoption.
The structural reasons inference spend accelerates:
- Always-on expectations: GenAI systems are expected to be continuously available, keeping GPU capacity provisioned even during demand troughs.
- Burst-driven concurrency: Product launches and usage spikes force infrastructure to be sized for peaks, not averages.
- Token inflation: Richer prompts and longer responses steadily raise compute cost per interaction.
- Latency constraints: Real-time experiences lock inference into premium, high-availability infrastructure.
- Low utilisation: Without intelligent scheduling, GPUs allocated for inference often operate far below capacity, leaving expensive compute under-leveraged even as costs remain fully realised.
Individually manageable, these forces combine to turn inference into a recurring cost curve that grows in step with business success.
Deployment Patterns That Quietly Shape Your Inference Bill
How GenAI is served often matters as much as how powerful the model is. Two organisations running the same model can see very different cost outcomes based on deployment choices. Some workloads are batch driven, such as offline document processing or large scale summarisation, where latency tolerance allows for scheduling and cost optimisation. Others are real time, powering copilots and customer interfaces that demand sub second responses and always on availability. Most enterprises now operate hybrid environments, where batch and real time pipelines compete for the same GPU pools.
The risk emerges when these patterns are treated uniformly. Without workload aware orchestration, enterprises end up paying real time prices for batch style workloads and overprovisioning infrastructure to manage conflicting performance demands. What looks like a capacity issue is often an architectural one, shaped by how inference workloads are classified, scheduled, and governed.
Why GPU Private Cloud Changes the Economics of Inference
Public cloud GPUs unlock speed and experimentation. At production scale, however, cost volatility, performance variability, and compliance complexity begin to surface as strategic risks rather than technical inconveniences.
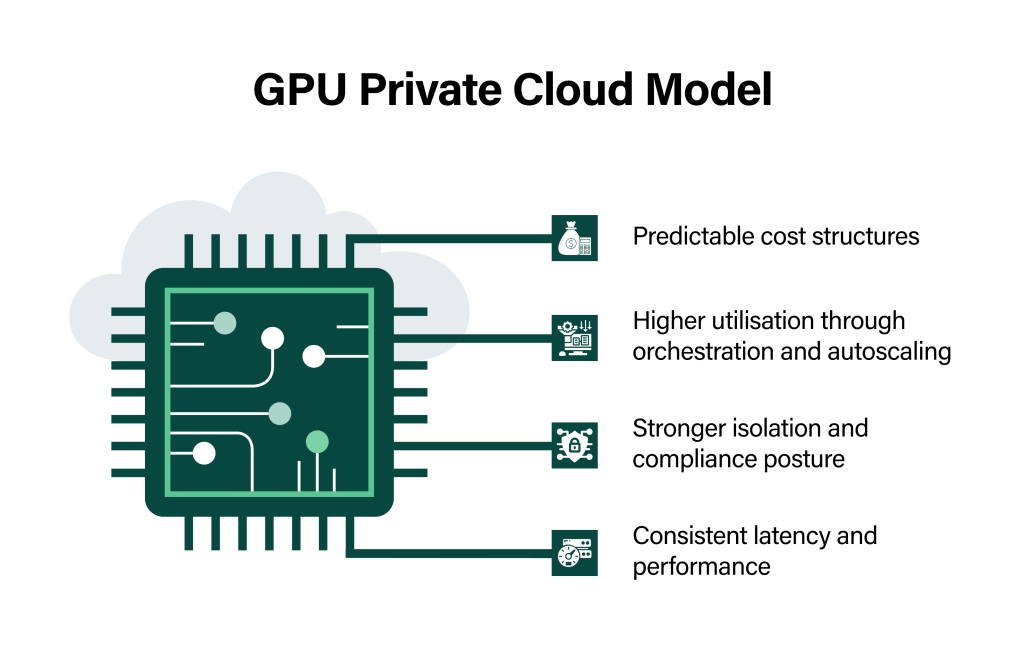
A GPU Private Cloud model rebalances the equation by offering:
- Predictable cost structures: Capacity planning replaces open ended consumption, bringing financial predictability to recurring inference workloads.
- Higher utilisation through orchestration and autoscaling: GPU pooling, intelligent scheduling, and demand-aware scaling reduce idle capacity.
- Stronger isolation and compliance posture: Dedicated environments simplify regulatory alignment, data residency, and audit readiness for sensitive workloads.
- Consistent latency and performance: Elimination of noisy neighbours ensures inference performance remains stable under load.
The outcome is not just lower unit cost. It is operational confidence. Inference becomes an engineered capability rather than an unpredictable expense line item.
The real cost drivers beyond GPU hours
Inference economics are shaped by more than GPU hours. Idle capacity reserved for low latency, rising network and data movement costs, and the operational overhead of monitoring and governance quietly inflate total cost of ownership. Over provisioned service levels often lock infrastructure into worst case design rather than real demand.
These costs are not wasted. They buy reliability. The leadership imperative is to make them visible and governable, instead of letting them hide inside aggregated cloud bills.
Readiness Checklist for Production Inference
Before GenAI inference becomes mission critical, leadership teams must ask a few uncomfortable questions.
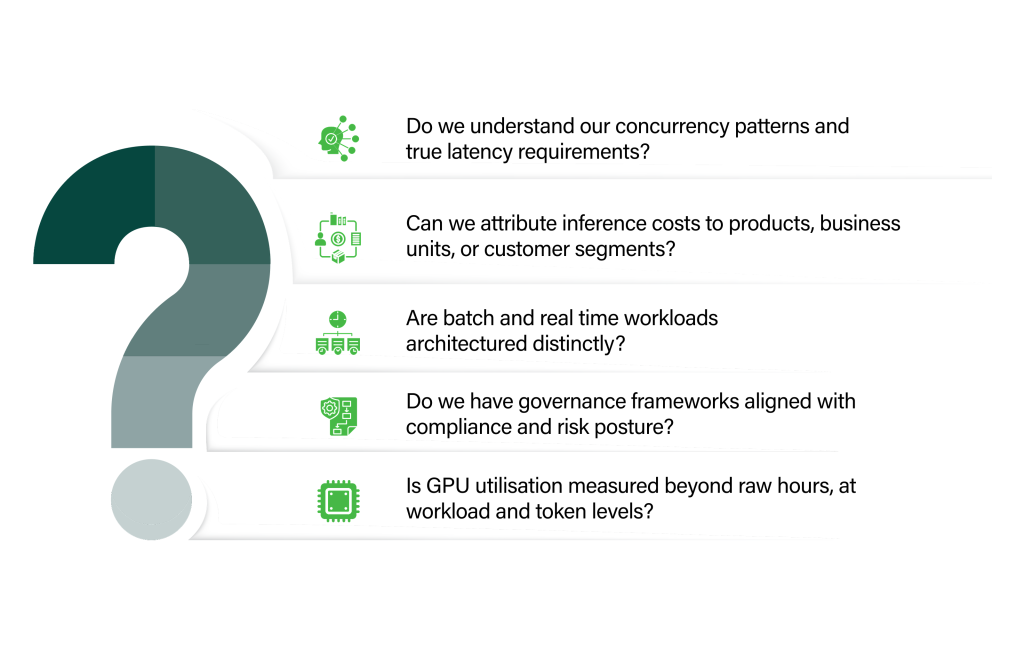
If the answer to any of these is no, costs are likely to spiral once traffic hits production volumes.
Inference is now a boardroom infrastructure conversation
By 2025, infrastructure strategy is no longer about servers and storage alone. It is about how intelligence is delivered at scale, under financial and regulatory discipline. According to IDC’s 2025 forecasts, global investment in AI inference infrastructure is expected to surpass spending on training infrastructure by the end of 2025, underscoring how inference workloads are increasingly driving demand for GPU-optimized systems.
This shift reframes data centre strategy, private cloud design, and GPU capacity planning. Inference is no longer an operational detail. It is a strategic economic variable in the digital operating model of the modern enterprise.
The most expensive GenAI architectures are not the ones that fail technically, but the ones that succeed in adoption without financial discipline. Inference has become the new cloud bill. It recurs, it scales with success, and it reflects architectural choices more than model sophistication. GPU Private Cloud offers enterprises a way to bring predictability, governance, and efficiency into this cost centre without compromising performance or compliance.
For CXOs shaping the next phase of digital transformation, the question is no longer whether GenAI will scale. It is whether the economics of inference will scale with it.
At CtrlS, we design GPU Private Cloud environments purpose built for production GenAI. If you are moving inference from pilot to platform, a focused architecture workshop can help map demand, risk, and cost before your next cloud bill becomes a boardroom agenda.

Srini Reddy, Vice President & Head - Service Delivery, CtrlS Datacenters
With over 25 years of experience in the IT industry, Srini is a seasoned leader in cloud and IT infrastructure solutions. At CtrlS, he is responsible for the overall operations, and customer service delivery. Srini holds a strong track record of leading and managing cross-geography teams and partners, delivering key business and technology transformations. His extensive expertise spans program and project management, as well as IT service management, IT strategy, and quality management.
 marketing@ctrls.in
marketing@ctrls.in