As AI workloads move from experimental to mission-critical, the infrastructure supporting them must evolve with equal seriousness – across power, cooling, sustainability, and water.
The data centre industry has absorbed many cycles of change, but the shift driven by artificial intelligence is different in character. Previous waves – cloud migration, virtualisation, mobile-driven scale, increased demand within existing infrastructure frameworks. AI is rewriting the frameworks themselves.
This is not a warning or a prediction. It is an observation visible in the numbers, in the engineering requirements customers are now presenting, and in the infrastructure decisions that forward-looking operators are making today. Understanding what AI actually demands of physical infrastructure, beyond the headline compute figures, is where the meaningful conversation begins.
From Incremental Growth to Structural Change
Traditional enterprise data centres were designed around rack densities of 5 to 10 kilowatts. That figure served as a reliable planning assumption for over a decade. It no longer does.
AI training clusters and inference environments operate comfortably at 30 to 100 kW per rack today. Advanced GPU configurations extend that envelope further, toward 200 to 250 kW. The significance of this shift is not just the number itself, it is what the number demands of every layer of infrastructure beneath it.
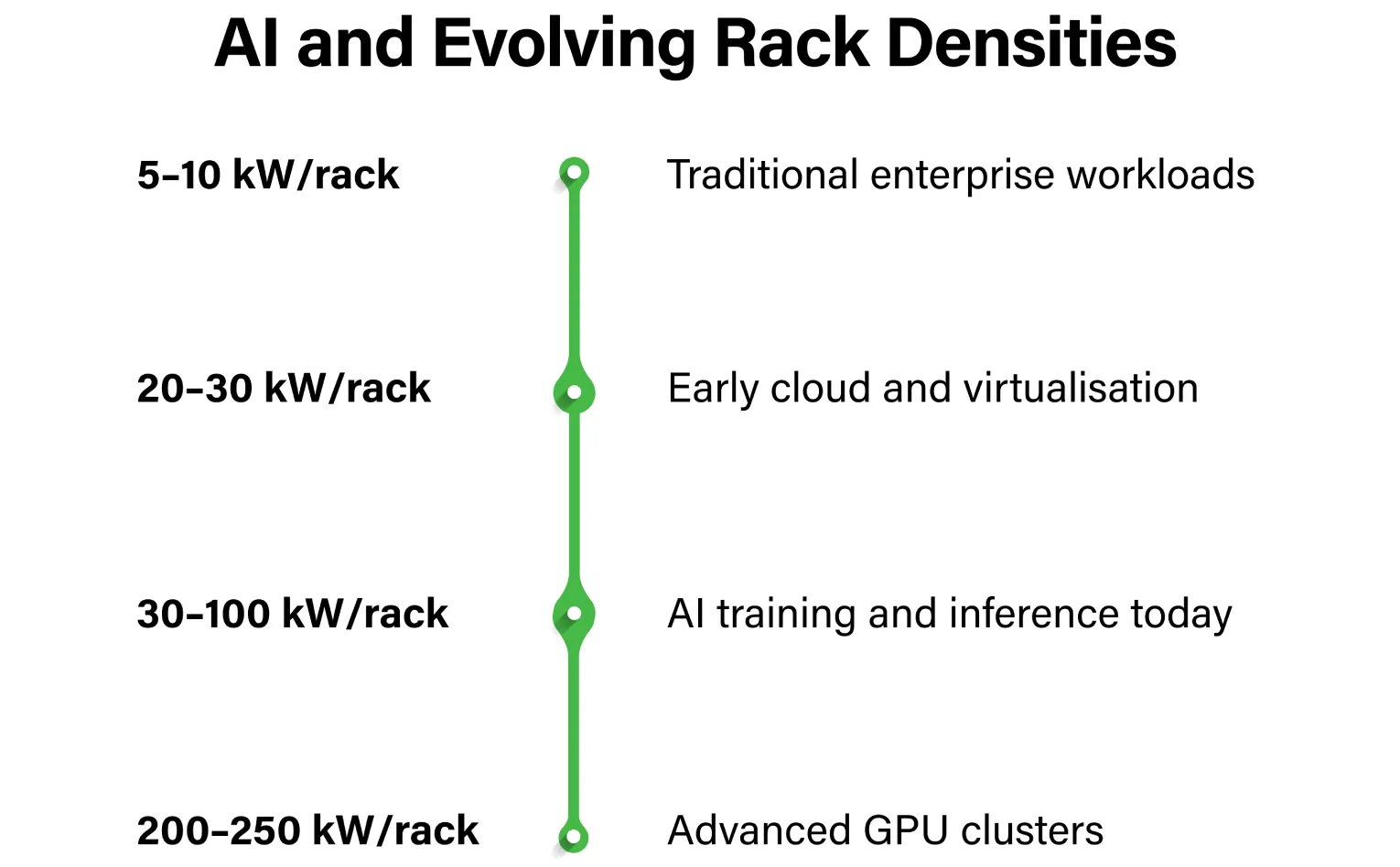
At these densities, the infrastructure must deliver across four dimensions simultaneously:
- Power architecture engineered for sustained high loads, not peak burst capacity
- Electrical topology with redundancy embedded at its core rather than added as an afterthought
- Cooling systems designed for continuous, intensive thermal output
- Modular scalability that allows capacity to grow without operational disruption
High-density AI environments surface design weaknesses quickly. Misaligned electrical topology, inadequate cable management, poorly coordinated mechanical systems, each of these create compounding inefficiencies under sustained load. Getting the foundational engineering right is not a premium option. It is the baseline requirement.
Rethinking Cooling Architecture
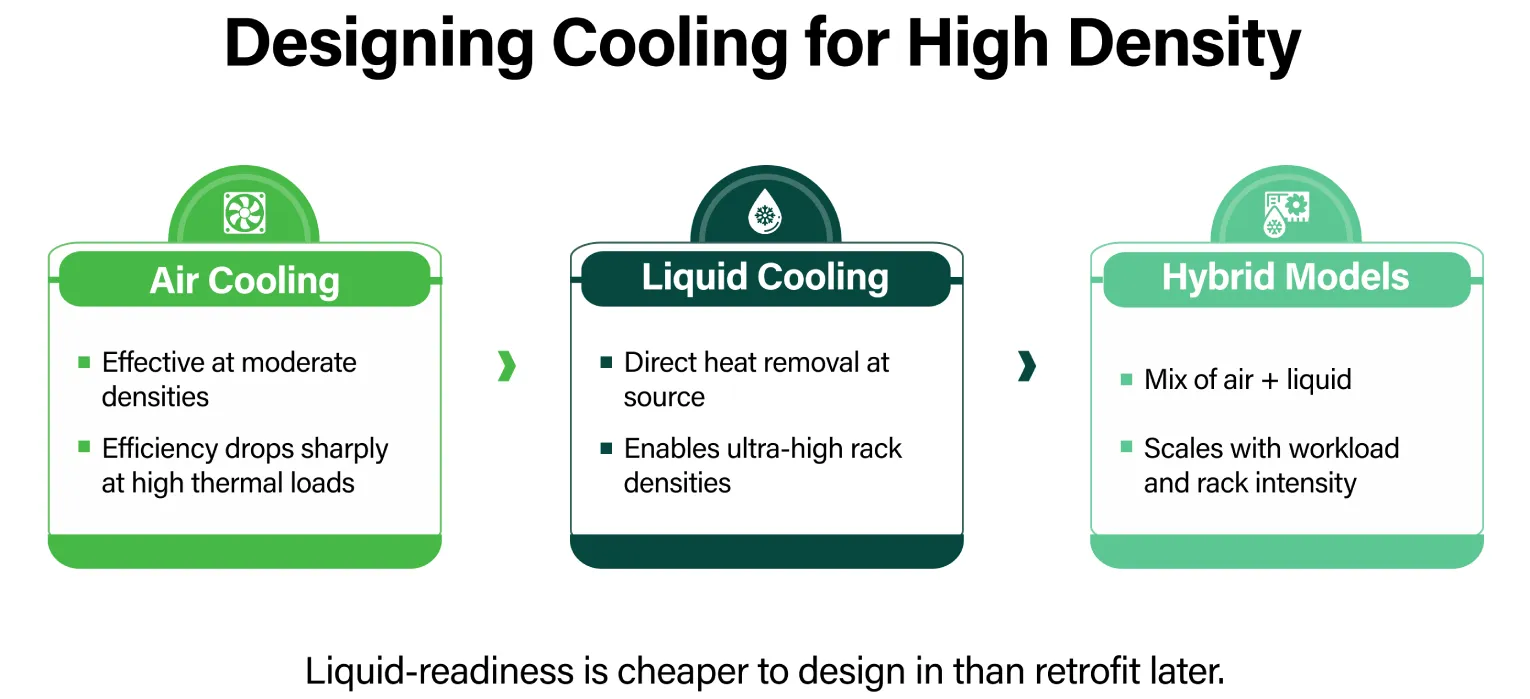
Air cooling remains a viable and well-understood approach at moderate densities, provided airflow engineering is properly optimised. The challenge is that AI workloads are pushing thermal output beyond what conventional air-based systems can manage without significant trade-offs in efficiency or reliability.
The strategic inflection point for most operators is not whether liquid cooling will eventually be necessary, but whether the facility is designed to accommodate it before that necessity becomes urgent. Retrofitting liquid infrastructure into a facility built solely for air cooling is expensive, operationally disruptive, and often constrained by the original mechanical layout.
The more considered approach is to build liquid-readiness into the structural layout from the outset. This means modular mechanical configurations capable of supporting three cooling models alongside existing air-based systems:
- Direct-to-chip liquid cooling, where coolant is delivered directly to the processor
- Immersion cooling, where servers are submerged in thermally conductive fluid
- Hybrid models that combine liquid and air handling depending on rack density and workload type
This phased approach allows density to increase over time without forcing structural rebuilds.
Within CtrlS AI-ready environments, this thinking already informs how new capacity is structured, supporting current densities from 30 kW to over 100 kW, with engineering provisions extending to 250 kW per rack.
Sustainability as Operational Discipline
The relationship between AI infrastructure and sustainability is one of genuine complexity. AI clusters consume significant power at high and continuous intensity. Managing that consumption responsibly, while meeting the performance expectations of customers running demanding workloads, requires discipline at every layer of facility design and operation.
What has changed in the market is that sustainability accountability has moved from corporate reporting into procurement requirements. Enterprise customers and hyperscalers increasingly require auditable data to support their own ESG disclosures. This includes:
- Alignment with international environmental management standards such as ISO 14001
- Third-party certified facilities with transparent PUE tracking
- Renewable sourcing agreements backed by long-term capacity commitments
- Carbon performance data that can be reported through recognised frameworks
For operators building AI-ready capacity at scale, treating sustainability as an auditable infrastructure discipline, rather than a communications function, is both the right approach and the commercially necessary one.
Water Strategy in a High-Density Environment
Cooling high-density infrastructure in India’s climate requires a deliberate and structured approach to water. Operators who rely primarily on freshwater consumption face real constraints, particularly during peak summer conditions when cooling demand is highest and ambient temperatures most challenging.
Advanced facilities are addressing this through a combination of approaches:
- Rainwater harvesting integrated into site-level water management
- Greywater reuse systems that reduce dependence on freshwater inputs
- Closed-loop recycling that minimises water loss through evaporation and discharge
- Cooling tower efficiency optimisation tuned for seasonal and load variation
Water-use intensity is becoming a standard line item in infrastructure due diligence, and operators who have built water stewardship into their foundational design are better positioned for those conversations.
Across key campuses operated by CtrlS – including Mumbai, Hyderabad, Noida, and Bengaluru – 70 to 90 percent of operational water is harvested and recycled, with nearly 10 billion litres managed through structured stewardship programmes.
What AI-Ready Infrastructure Actually Requires
The phrase ‘AI-ready’ has become widely used, and with that usage has come some imprecision about what it actually means. It is worth being direct about this.
An AI-ready facility is not defined by the presence of GPU hardware. It is defined by whether the underlying infrastructure can support that hardware continuously, efficiently, and at the reliability standards that mission-critical workloads require.
In practice, that means three things:
- Stable, scalable power delivery engineered for sustained high loads — not intermittent peaks
- Precision cooling designed specifically for the thermal profile of GPU clusters, not adapted from systems built for a different era
- Structural and mechanical flexibility that accommodates evolving density requirements without forcing customers to choose between performance and operational continuity
The foundational principles of data centre operation – uptime, resilience, efficiency, operational discipline, do not change with AI. What changes is the intensity at which those principles must be applied, and the sophistication of the engineering required to maintain them.
Operators who understand this distinction, and who have built their infrastructure accordingly, are well placed for what the next phase of AI deployment demands. Those who have treated AI-readiness as primarily a marketing position will find the gap between claim and capability increasingly difficult to sustain.
Looking Ahead
The infrastructure requirements of AI will continue to evolve as model complexity increases, inference workloads scale, and enterprise adoption deepens. Rack densities will rise further. Liquid cooling will become standard rather than specialist. Sustainability accountability will tighten. Water discipline will move from differentiator to expectation.
The data centre operators who will define infrastructure standards over the next decade are those building for that trajectory now, embedding liquid-readiness structurally, designing power systems for continuous high load, treating sustainability as verifiable infrastructure performance, and managing water as a constrained operational resource.
The industry is at an inflection point that rewards preparation over reaction. The engineering decisions being made today in AI-ready facilities will shape what is possible and what is not – for the customers and workloads that arrive tomorrow.

Vipin Jain, President – Hyperscale Growth, Delivery & Innovation, CtrlS Datacenter
Vipin spearheads the expansion of CtrlS’s hyperscale services in India and international markets, deepening strategic engagement with global hyperscalers, and driving the timely execution of complex fit-out projects for both hyperscale and enterprise clients. He also leads innovative initiatives focused on automation, sustainability, and green datacenters, ensuring that CtrlS continues to set industry benchmarks in reliability, efficiency, and sustainable growth.
 marketing@ctrls.in
marketing@ctrls.in