A single NVIDIA GB200 NVL72 rack draws up to 140 kW of power. The traditional enterprise data center was designed for 10 to 15 kW per rack. That is not a gap you close with a facilities upgrade. It is a different engineering problem entirely.
Traditional server racks consume 5 to 15 kW, while AI-optimised racks with high-performance GPUs require 40 to 60+ kW, with cutting-edge AI training facilities pushing individual racks to 100+ kW. Average rack power density is expected to rise from 36 kW per rack in 2023 to 50 kW per rack by 2027, and the economics of AI infrastructure are scaling at the same pace. Global AI data center capital expenditure is projected to reach $450 billion in 2026 and $1 trillion by 2028.
Most enterprise data centers were not built for any of this. The architecture, the cooling, the power delivery, the electricity consumption, the internal network fabric, all of it was designed for a different class of workload. Retrofitting is possible in limited cases, but the difference between a traditional data center and a purpose-built AI factory is wider than most infrastructure teams realise until they are already mid-deployment.
This blog maps where the two models diverge across five critical dimensions: power density, cooling architecture, network fabric, resiliency requirements, and total cost of ownership.
By the end, you will know exactly which workloads belong in each environment and what to look for in an infrastructure partner that can actually support AI at scale.
What defines a traditional datacenter?
Traditional enterprise data centers were engineered around a specific workload profile: CPU-based servers running databases, ERP systems, virtualised applications, and storage. The design baseline assumed 5 to 10 kW of power per rack.
In such data centers, raised floors managed airflow. There were hot aisle and cold aisle containment that kept temperatures predictable. Computer Room Air Conditioning (CRAC) units handled the cooling load. It worked reliably for decades because the workloads were stable, the heat output was manageable, and demand grew incrementally.
Power and network architecture built for steady-state loads
The power redundancy model followed N+1 or 2N configurations, designed for predictable, continuous draws rather than the sharp, variable spikes that GPU clusters produce. Network topology was built for client-server traffic and east-west application communication, not the high-throughput, low-latency GPU-to-GPU fabric that AI training demands.
Still the right fit for the right workloads
Traditional data centers are not obsolete. They remain the correct infrastructure choice for general business applications, disaster recovery, regulatory archiving, and any workload that does not require extreme power density.
The problem is not the facility. It is the assumption that the same facility can absorb a fundamentally different class of compute without structural rethinking. Assuming this is even more wrong, when we already know that cooling systems, computing power, and server resources now consume almost 80% of the energy.
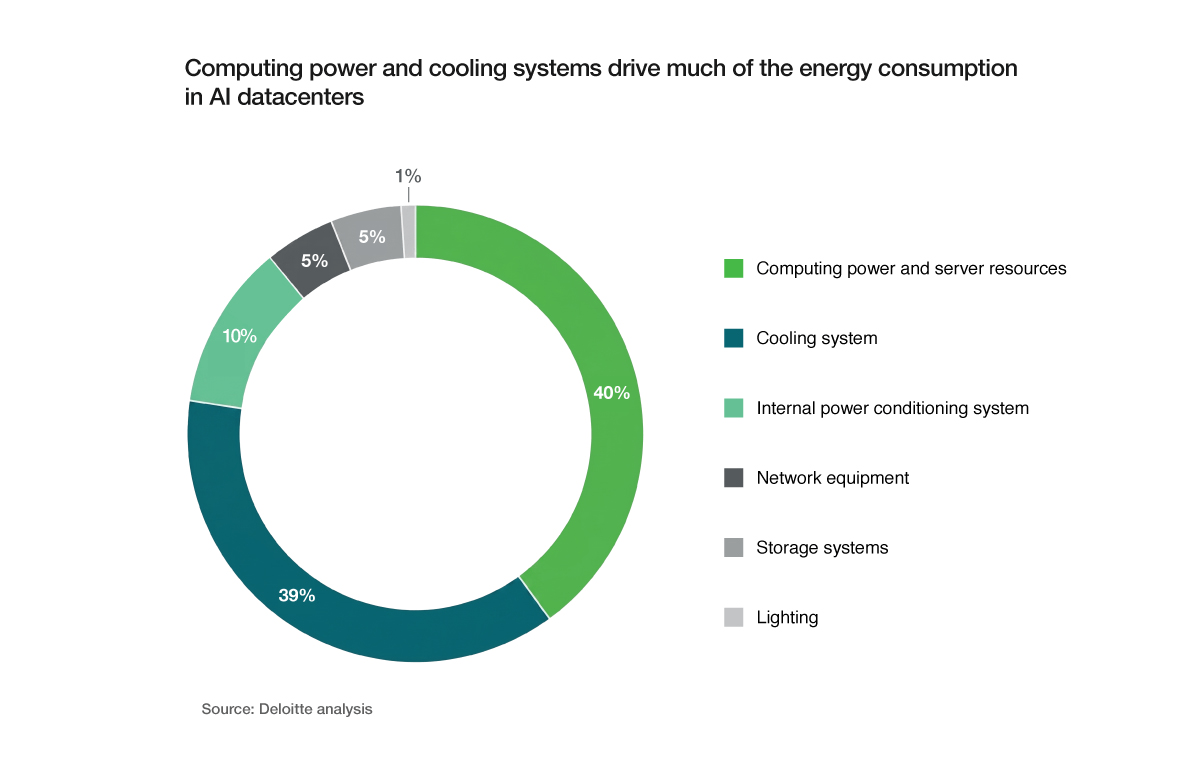
What makes an AI factory structurally different
As we mentioned, the gap between a traditional data center and an AI factory is not a matter of scale. It is a matter of architecture.
AI factories are purpose-built facilities where every design decision, from civil construction to power delivery to internal networking, is made around the thermal and computational demands of GPU clusters.
Changing one element in isolation does not work. The power density, cooling system, network fabric, and resiliency model are co-dependent. You either build for AI from the ground up, or you spend significantly more money working around the constraints of a facility that was never designed for it.
1. Power density: the dimension that changes everything
A single NVIDIA GB200 NVL72 rack draws 120 to 140 kW. A traditional enterprise data center built for 10 to 15 kW per rack cannot physically support these systems without full infrastructure redesign.
That redesign touches everything: high-amperage power distribution units, transformer capacity rated for AI loads, UPS architecture that can handle the sharp, variable draw of GPU clusters rather than the steady-state consumption of CPU servers. Rack spacing changes. Floor loading limits change. Cable management changes.
Power delivery is as much a constraint as cooling. Before evaluating any colocation partner for AI workloads, ask one specific question: what is the maximum per-rack power capacity you can deliver today, and what is the path to increase it without taking the facility offline?
2. Why retrofitting traditional facilities falls short
While most traditional facilities were designed for predictable loads, GPU clusters do not draw power predictably. They spike during training runs, throttle during checkpointing, and surge again at scale.
The civil and electrical infrastructure of a legacy facility, including its substation capacity, transformer ratings, and floor load tolerances, was not specified for this profile.
Adding capacity after the fact is possible, but it is expensive, disruptive, and often constrained by the original structural design in ways that are not visible until construction begins.
3. Cooling architecture: when air is no longer enough
Standard air cooling works up to about 30 kW per rack before it becomes impractical. At 60+ kW, air cooling requires so much airflow that it consumes significant power itself and creates hot spots regardless.
AI factories address this through three primary approaches: rear-door heat exchangers that capture exhaust heat before it enters the hot aisle, direct-to-chip liquid cooling that routes coolant directly to GPU heatsinks, and full liquid immersion cooling where servers sit in dielectric fluid.
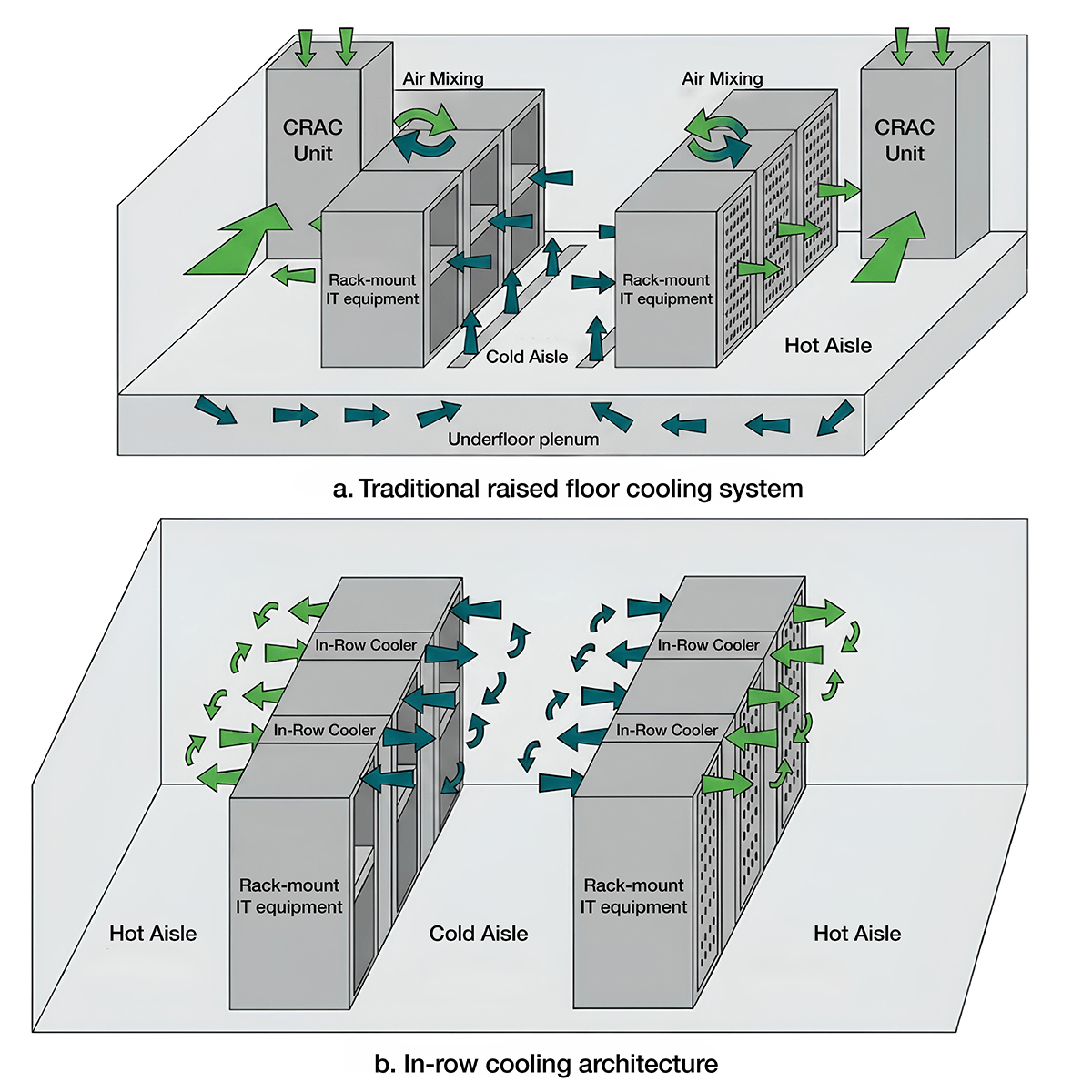
The PUE implications are significant. Liquid cooling systems can achieve a design Power Usage Effectiveness (PUE) of 1.35. Legacy air-cooled facilities typically run at 1.6 or higher. That difference compounds over a three to five-year GPU cluster lifecycle into a material reduction in energy cost per GPU hour.
In 2022, the average annual PUE was 1.55. We are in 2026 now and that number is not going to cut it anymore.
Liquid immersion cooling, specifically, delivers up to 40% lower energy cost and reduces CO2 footprint by 25% compared to conventional methods. CtrlS data centers support all three cooling strategies across their high-density AI-ready campuses, with civil design, drainage, and power layout co-engineered from the start rather than retrofitted.
3. Purpose-built cooling vs bolted-on upgrades
The structural difference matters here. Adding liquid cooling to a facility designed for air handling runs into constraints that are not always obvious upfront: ceiling height, drainage routing, floor penetrations, and load-bearing limits.
Purpose-built liquid cooling infrastructure eliminates these constraints because the civil design accounts for them from day one. The cooling model is not an add-on. It is the foundation on which everything else is sized.
4. Network fabric: GPU-to-GPU communication at scale
Inside an AI factory, the binding constraint during a training run is often not compute capacity or power. It is the speed at which GPUs can communicate with each other.
Standard enterprise networking was designed for client-server and east-west application traffic. It is the wrong tool for GPU cluster interconnect.
AI factories use InfiniBand or RDMA over Converged Ethernet (RoCE) for internal cluster fabric, with fat-tree or spine-leaf topologies that minimise latency between nodes. External connectivity matters equally: carrier-neutral fabric, direct cloud on-ramps, and internet exchange hosting all reduce the latency and cost of moving large datasets into the facility for training.
5. Resiliency requirements: uptime means something different for AI
A 20-hour model training run interrupted by a 30-minute power event does not simply pause. Without checkpoint recovery in place, it restarts. That changes how infrastructure teams should think about uptime SLAs for training workloads.
AI inference, by contrast, has zero tolerance for interruption. Models serving end users in production carry the same uptime requirements as any mission-critical enterprise application.
Rated-4 operational sustainability is not over-engineering for production AI environments. It is the appropriate baseline. CtrlS maintains a 99.995% uptime SLA across its Rated-4 certified facilities, which is directly relevant for enterprises running AI inference at scale.
How enterprises are making the transition in practice
The shift from traditional data center to AI factory does not happen in one move for most enterprises. It happens in deliberate stages, with each infrastructure decision building on the last. These steps give infrastructure leaders a practical starting point.
- Audit your current rack density utilisation before assuming your existing facilities cannot support AI workloads. Many enterprise data centers are underutilised, and lighter GPU workloads can run at 30 to 40 kW per rack in partially upgraded environments.
- Separate training workloads from inference workloads in your infrastructure planning. Training tolerates slightly more flexibility on uptime, while inference carries production-grade availability requirements and should be hosted accordingly.
- Evaluate colocation partners on power headroom and cooling architecture first, price second. The ability to scale from 20 kW to 80 kW per rack within the same facility, without a disruptive migration, is worth more than a lower headline rate that caps your growth.
- Model your total cost of ownership over 36 months, not just monthly rack costs. A facility with a design PUE of 1.35 versus 1.6 produces a significant reduction in energy expenditure at GPU cluster scale, and that difference compounds.
- Verify external connectivity at the facility level. AI workloads require high-volume data ingestion and low-latency cloud access that generic managed connectivity cannot reliably support.
Choosing the right infrastructure for the AI era
The separation between AI factories and traditional data centers is not a technology trend to monitor. It is a hard engineering reality that is already shaping infrastructure decisions across every sector.
Enterprises that plan GPU deployments on the same assumptions they applied to ERP rollouts will hit power, cooling, and network ceilings faster than their roadmaps anticipate.
The right approach is not to abandon traditional data centers. It is to be precise about which workloads belong where, and to choose infrastructure partners who have already solved the hard problems at scale.
For enterprises running production AI inference or large-scale GPU training in India, CtrlS has built high-density AI-ready infrastructure to match.
The Hyderabad Chandanvelly campus spans 700 MW, expandable to 1.2 GW, with an ultra-high-density, AI-first design and advanced cooling and power infrastructure purpose-built for demanding workloads.
The Hyderabad Pharma City Green Campus adds 750 MW, also expandable to 1.2 GW, designed for 100% round-the-clock renewable energy and India’s largest green data center footprint.
Across all campuses, CtrlS supports rack densities of up to 250kW per rack, with N+1 / N+N cooling capacity in 45°C ambient conditions, with direct-to-chip liquid cooling, liquid immersion cooling, and a design PUE as low as 1.35.
If you are evaluating AI infrastructure in India, speak to a CtrlS specialist about power headroom, cooling architecture, and deployment timelines at your target location. Contact CtrlS.

Rahul Dhar President - Global Datacenter Operations, CtrlS Datacenters
With nearly two decades of leadership experience leading critical infrastructure and technology teams, Rahul Dhar brings a deep understanding of managing and scaling mission-critical datacenter operations. At CtrlS, Rahul leads the company’s global operations charter. He is also responsible for ensuring operational resilience and reliability, improving uptime and recovery, and coordinating across infrastructure, facilities, and support functions to maintain the highest standards of service quality across CtrlS’ expanding global footprint. He recently served as the Country Director - Datacenters at Microsoft India. Previously, he has held senior leadership roles at Tata Communications, COLT, and Vodafone, where he led cross-geographic teams, delivered large-scale programs, and drove major process transformations across global operations.
 marketing@ctrls.in
marketing@ctrls.in