Artificial intelligence has fundamentally changed enterprise infrastructure decisions. For more than a decade, the default response to most compute questions was simple: move it to the cloud.
In 2026, that assumption is beginning to shift, particularly for GPU workloads.
Organizations deploying AI at production scale are discovering that infrastructure decisions made during pilot projects do not always hold once workloads expand across departments and use cases. What worked for a short proof of concept can become inefficient or expensive when applied to continuous enterprise operations.
This guide provides a practical framework for CIOs and infrastructure leaders evaluating one of the most important infrastructure decisions of the decade: which AI workloads belong on public cloud GPUs and which are better suited for dedicated GPU private cloud environments.
1. The Enterprise GPU Decision Problem
Two major shifts have reshaped enterprise infrastructure strategy.
First, AI workloads behave very differently from traditional enterprise applications. Modern AI systems are GPU intensive and often involve complex pipelines rather than a single model. A single AI assistant can quickly evolve into multiple specialized agents handling retrieval, reasoning, ranking, and orchestration.
Because the value of adding AI capabilities is high, adoption spreads rapidly across organizations. Finance teams deploy fraud detection models. HR teams automate document processing. Customer support introduces AI agents. Product teams embed generative features into applications.
However, the marginal infrastructure cost of each new AI use case can increase rapidly if compute architecture is inefficient.
This analysis shows that specialized GPU cloud providers can offer 40–70% lower pricing compared to traditional hyperscale cloud platforms for high-end GPUs such as NVIDIA H100 and H200.
As a result, enterprises that made GPU decisions during early experimentation phases are now reassessing those choices as AI workloads reach production scale.
The key insight is simple.
Every GPU workload has a natural home. That home depends on four factors:
- compute pattern
- data sensitivity
- latency requirements
- cost structure
Understanding these factors helps infrastructure teams place each workload in the most appropriate environment.
2. Workload Taxonomy: Know What You Are Running
Enterprises often treat all AI workloads as identical. In reality, different AI tasks require very different infrastructure models.
- Foundation Model Training
Training large models from scratch involves massive datasets and thousands of GPUs running for weeks. For most enterprises, this is rare and typically limited to hyperscalers or research labs.
These workloads benefit from highly parallel compute clusters and strong data isolation, making dedicated clusters or reserved hyperscaler capacity the most suitable infrastructure.
- Fine Tuning and Domain Adaptation
Fine tuning adapts existing foundation models such as Llama, DeepSeek, or Mistral to enterprise data including financial transactions, clinical notes, or internal knowledge bases.
These jobs typically run for hours or days but involve highly sensitive proprietary datasets. For regulated industries such as banking or healthcare, private GPU environments simplify compliance and auditing.
Fine tuning is therefore one of the clearest use cases for GPU private cloud deployments.
- Batch Inference
Batch inference runs predictions across large datasets at scheduled intervals. Examples include document classification, historical fraud analysis, and analytics pipelines.
These workloads operate in predictable bursts and usually do not require real time responses. Public cloud GPUs often work well for non sensitive batch processing, while private infrastructure becomes attractive when organizations require predictable cost structures.
- Real Time Inference
Real time inference powers live AI applications such as fraud detection, customer support agents, and AI copilots.
These systems require continuous GPU availability and low latency responses. Because workloads run persistently and interact with sensitive customer data, dedicated GPU infrastructure often provides more reliable performance.
- VDI and Visual Workloads
Many enterprises also use GPUs for simulation, rendering, and GPU accelerated virtual desktops.
These workloads follow predictable usage patterns and often benefit from reserved GPU capacity rather than variable public cloud pricing.

3. The Decision Matrix: Right Workload, Right Infrastructure
Once workloads are categorized, infrastructure decisions become clearer.
Five factors typically determine whether workloads belong on public cloud GPUs or dedicated GPU private cloud infrastructure.
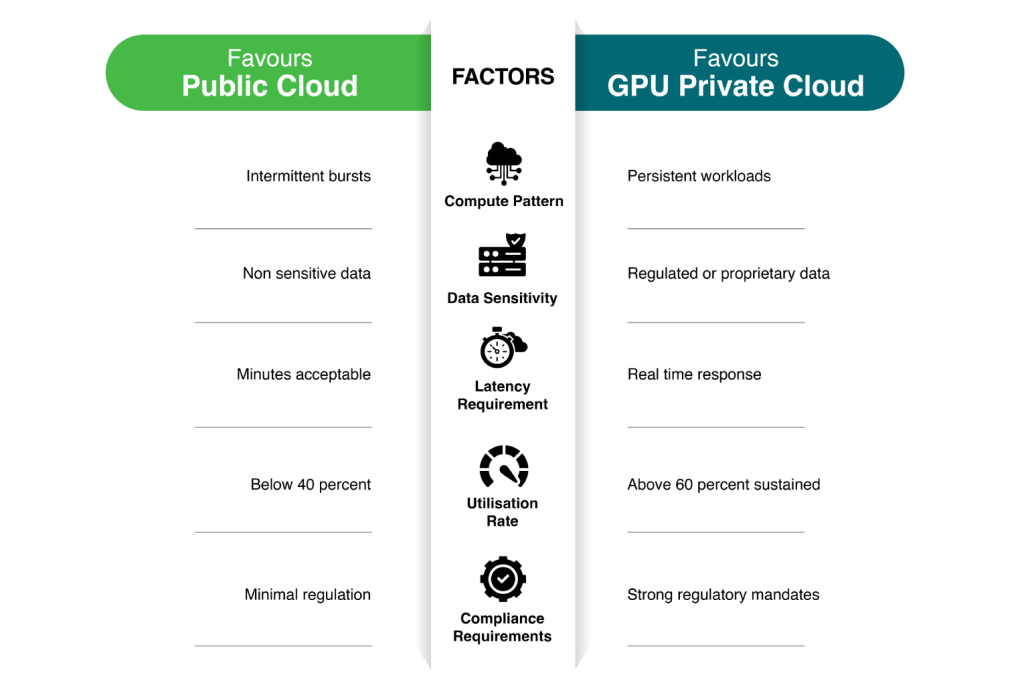
Utilization rate is one of the most important variables.
Private infrastructure becomes economically advantageous primarily when GPU utilization exceeds roughly 60%. Below that threshold, variable public cloud pricing may remain more cost effective.
Compliance can also override cost considerations. For many regulated industries, infrastructure decisions are driven by data governance requirements rather than purely economic factors.
4. Data Sovereignty and Security
For regulated industries, infrastructure choices are not purely technical or financial decisions. They are regulatory decisions.
Organizations in financial services, healthcare, and government sectors must maintain strict control over sensitive data and processing environments.
Private infrastructure offers a key advantage by providing clear and auditable control over data processing locations.
In shared public cloud environments, security responsibility is distributed between provider and customer. While secure, this model can complicate regulatory audits and data residency requirements.
Private infrastructure environments provide:
- clearly defined hardware ownership
- transparent data processing locations
- simplified audit trails
Regulatory frameworks such as the Digital Personal Data Protection Act and the RBI IT framework increasingly require enterprises to demonstrate control over where sensitive data is processed and stored.
In such cases, private GPU infrastructure becomes the most practical architecture.
5. Where GPU Private Cloud Platforms Fit
GPU hardware alone is not enough to run enterprise AI systems.
Production deployments require orchestration layers, model routing frameworks, enterprise search pipelines, and governance tools.
Dedicated GPU infrastructure combined with integrated AI platforms enables organizations to deploy these capabilities faster while maintaining cost efficiency.
Platforms such as CtrlS GPU Private Cloud paired with the Neutrino AI framework provide this integrated stack. Dedicated GPU clusters hosted in Rated 4 data centers deliver predictable performance, low latency connectivity, and strong compliance controls.
At the application layer, Neutrino provides multi-model routing, enterprise search, workflow automation, and governance tools required to operate production AI systems.
Enterprises can begin on public cloud environments and migrate workloads to GPU private cloud infrastructure as AI deployments scale.
Conclusion
The GPU infrastructure decision in 2026 is not binary.
Enterprises do not need to choose between public cloud or private cloud for every workload. Instead, AI infrastructure should be treated as a portfolio strategy.
Workloads should be placed in the environment that best matches their compute pattern, sensitivity, latency requirements, and utilization profile.
When organizations apply this framework, a clear pattern usually emerges. The workloads closest to core operations, those involving sensitive data and sustained usage, naturally move toward dedicated GPU infrastructure.
Experimental and intermittent workloads continue to benefit from the flexibility of public cloud environments.
Designing this hybrid GPU strategy is quickly becoming one of the defining infrastructure decisions for enterprises entering the AI era.

Ankush Bansal, Senior Vice President - Presales, CtrlS Datacenters
With over 20 years of rich experience in presales and solution design, Ankush is a seasoned expert driving large-scale IT, cloud, and datacenter transformations. Skilled in leading C-level engagements, AI OPS-driven managed services, and complex enterprise transformation across BFSI, manufacturing, government, and more, Ankush has a proven track record of delivering cutting-edge solutions in cloud, cybersecurity, networking, and hyperscale infrastructure.
 marketing@ctrls.in
marketing@ctrls.in