About 78% of enterprises have AI agent pilots running. Fewer than 15% have moved any of them to production scale.
Gartner projects that over 40% of agentic AI projects will be canceled by the end of 2027 due to escalating costs, unclear business value, or inadequate risk controls.
The bottleneck, in most cases, is not the model. It is the infrastructure beneath it.
“AI-ready” has become the most overloaded phrase in datacenter sales. Every provider claims it. Few can define it with specificity, in terms of sustained rack power density, cooling modality, deployment timelines, or regulatory posture.
Less than 10% of existing datacenter inventory is capable of handling true AI-dense critical loads, yet the marketing says otherwise.
For enterprises committing to multi-year infrastructure decisions, the cost of choosing wrong means delayed AI rollouts, stranded capital, and a competitive gap that compounds every quarter a competitor ships faster.
The seven questions in this piece are designed to close that gap, before you sign anything.
Let’s dive right in!
If you’re evaluating providers against these criteria, CtrlS is built to answer every one of them:
- Asia’s largest Rated-4 operator, with 99.995% uptime SLA across 19 facilities in 9 cities, backed by 18+ years of operational track record.
- A committed 2 GW expansion roadmap with shovel-ready campuses in Mumbai and Hyderabad, captive solar through GreenVolt, and the trust of 5 of the world’s top 7 hyperscalers as independent market validation
7 Questions to Ask Before Choosing an AI-Ready Datacenter
The questions below are not a checklist. They are a pressure test. A provider that can answer all seven (with specifics) is one worth shortlisting. One that hedges on even two of them is telling you something important before you’ve signed anything.
Q1: What Power Density Can You Actually Sustain Per Rack?
“AI-ready” starts with power. And power is where most claims collapse first. Traditional colocation is engineered for 5-10 kW per rack. A GPU training cluster demands 80-160 kW. That is not a performance upgrade; it is a categorically different infrastructure requirement.
The question to ask is not “what’s your maximum?”
It is: is that ceiling a guaranteed per-rack commitment, or a facility-wide average that gets diluted the moment a dense neighbour moves in?
Push further with question like:
- What is the power delivery architecture?
- Busbar, overhead, under-floor?
- What PDU and UPS redundancy exists specifically at high-density zones?
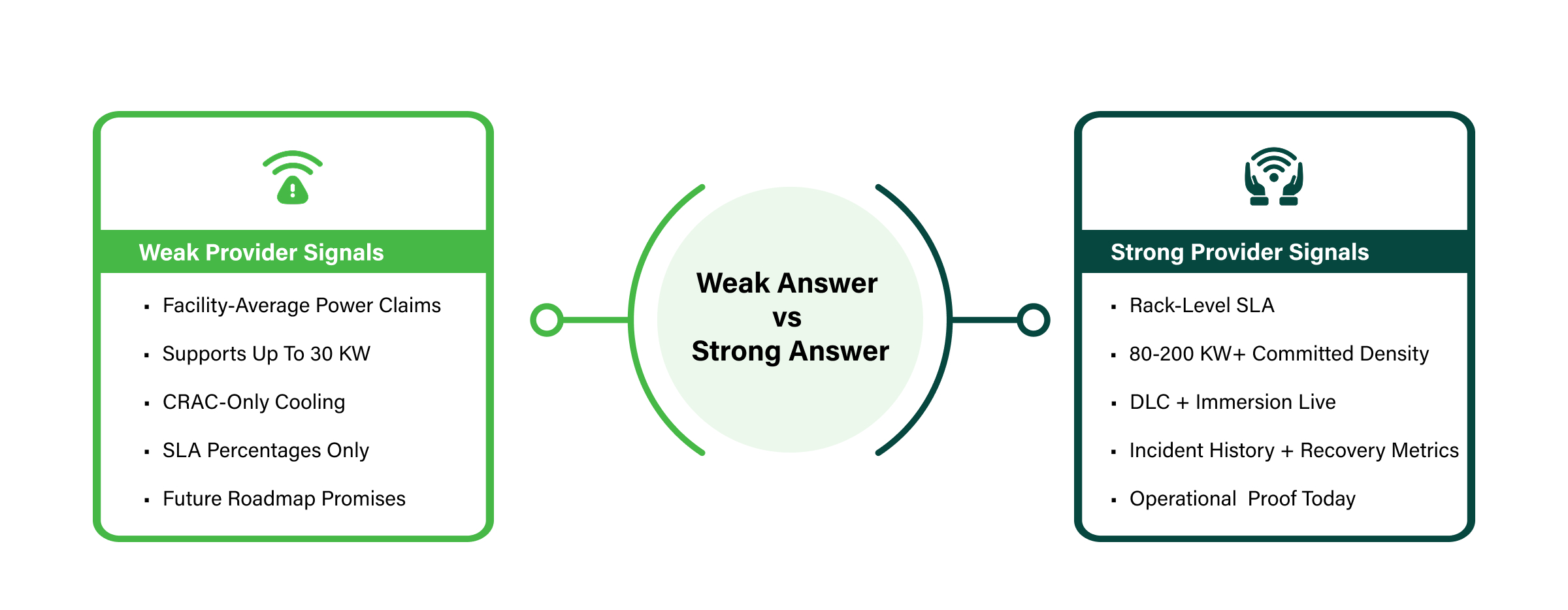
A weak answer sounds like: “We support up to 30 kW per rack.” That is inadequate for inference and untenable for training. A strong answer comes with documented high-density zones, dedicated power circuits, transformer-level redundancy, and confirmed headroom to scale beyond 200 kW without a facility redesign.
Ask for a rack-level power SLA in writing, not a facility average.
Q2: Which Cooling Architectures Are Live in Your Facility (Today)?
Cooling is where most “AI-ready” claims fall apart under scrutiny. Air cooling reaches its thermal ceiling around 35 kW per rack. Direct liquid cooling handles 70–160 kW. Liquid immersion can cut cooling energy consumption by up to 95%. The architecture a provider has deployed determines what workloads their facility can realistically absorb.

Ask whether the facility can support rear-door heat exchangers, liquid immersion cooling and direct-to-chip lines today and what the lead time looks like to upgrade without disrupting co-located workloads already running.
A weak answer references CRAC units and hot/cold aisle containment.
A strong answer describes multiple cooling strategies and modalities running simultaneously, with documented PUE targets of 1.2-1.35 for high-density AI zones specifically.
Ask for the PUE figure for high-density zones, the facility average will always look better than the number that actually applies to your workload.
Q3: What Is Your Verified Uptime Record, Not Your Stated SLA?
Any provider can put 99.995% on a datasheet. The figure that actually matters is what their infrastructure delivered across the last three to five years, at the facility level, under real operating conditions.
Start with certification. Rated-4 certification requires operational verification, not just design compliance.
Then go deeper:
- What are the N+1 or 2N configurations for power, cooling, and network independently?
- What is the documented recovery time objective following a power event?
You’ll get the real answers via incident logs, not SLA.
A weak answer restates the SLA percentage without explaining the redundancy architecture behind it. A strong answer specifies concurrent maintainability, independent power feeds, multi-zone physical security, and points to a verifiable track record across years of operation.
Ask what happened during their last power event, how long recovery took, and what was affected. A provider with nothing to report either hasn’t been tested or isn’t being transparent.
If the answer stays generic, the risk stays yours.
Q4: How Do You Handle Data Sovereignty and AI Compliance Mandates?
For enterprises in BFSI, healthcare, government, and telecom, infrastructure decisions carry regulatory consequences. Data processed through AI models must reside within defined jurisdictions — and India’s DPDP Act, RBI IT guidelines, and SEBI mandates are explicit about where that data can sit and how it must be governed.
The questions worth asking are specific:
- Are all facilities wholly within India, with no cross-border routing at any layer of the stack?
- Which datacenter compliance certifications are current – ISO 27001, SOC 2, PCI-DSS, and when were they last audited?
- Does the provider have documented deployments with regulated institutions, with audit trails that have survived regulatory scrutiny?
A weak answer is “we’re compliant” with no certifications named, no sector-specific deployments referenced, and no audit history to point to.
A strong answer describes native data sovereignty built into the infrastructure architecture, active certifications, and a track record of supporting regulatory audits for institutions in your sector.
Ask which specific regulatory audits they have supported for clients in your industry in the last 18 months and ask to speak to one of those clients.
Q5: What Is Your Renewable Energy Strategy and Does It Show Up in My ESG Numbers?
A 1,000-GPU cluster running continuously can consume as much power as a small town. For enterprises reporting under BRSR or CSRD frameworks, the energy profile of their datacenter provider feeds directly into their own Scope 2 emissions accounting. This makes the provider’s renewable energy posture a compliance input, not just a sustainability preference.
The distinction that matters here is between captive renewable generation and purchased renewable energy certificates.
RECs allow a provider to claim renewable credentials without changing how their facility is actually powered. Captive solar, by contrast, means generation capacity they own and operate.
Ask what percentage of current power draw comes from captive sources, what the trajectory looks like year on year, and whether they can provide facility-level energy data in a format your ESG reporting team can use directly.
Ask whether monthly renewable energy certificates and facility-level PUE data can be delivered in a structured format, and confirm this before contract, not after.
Q6: What Is Your Committed Timeline from Contract to Live AI-Ready Capacity?
In markets where datacenter build timelines routinely stretch 24 to 72 months, time-to-live has become a direct input to AI competitiveness.
GPU procurement windows are compressed. Model deployment timelines are aggressive. An enterprise that secures compute before its infrastructure is ready is not ahead, it is waiting.
The meaningful question is about ownership across the build chain.
A provider still in permitting for land, negotiating power access, or dependent on third-party construction firms carries timeline risk at multiple points simultaneously.
A provider with in-house design, engineering, and construction teams and pre-secured land and power, controls those dependencies.
Ask for a committed timeline from LOI to live rack, with contractual milestones attached, and ask what the remediation looks like if a milestone slips.
Map every dependency in the build chain and ask who owns it. The answer will tell you where the schedule risk actually lives.
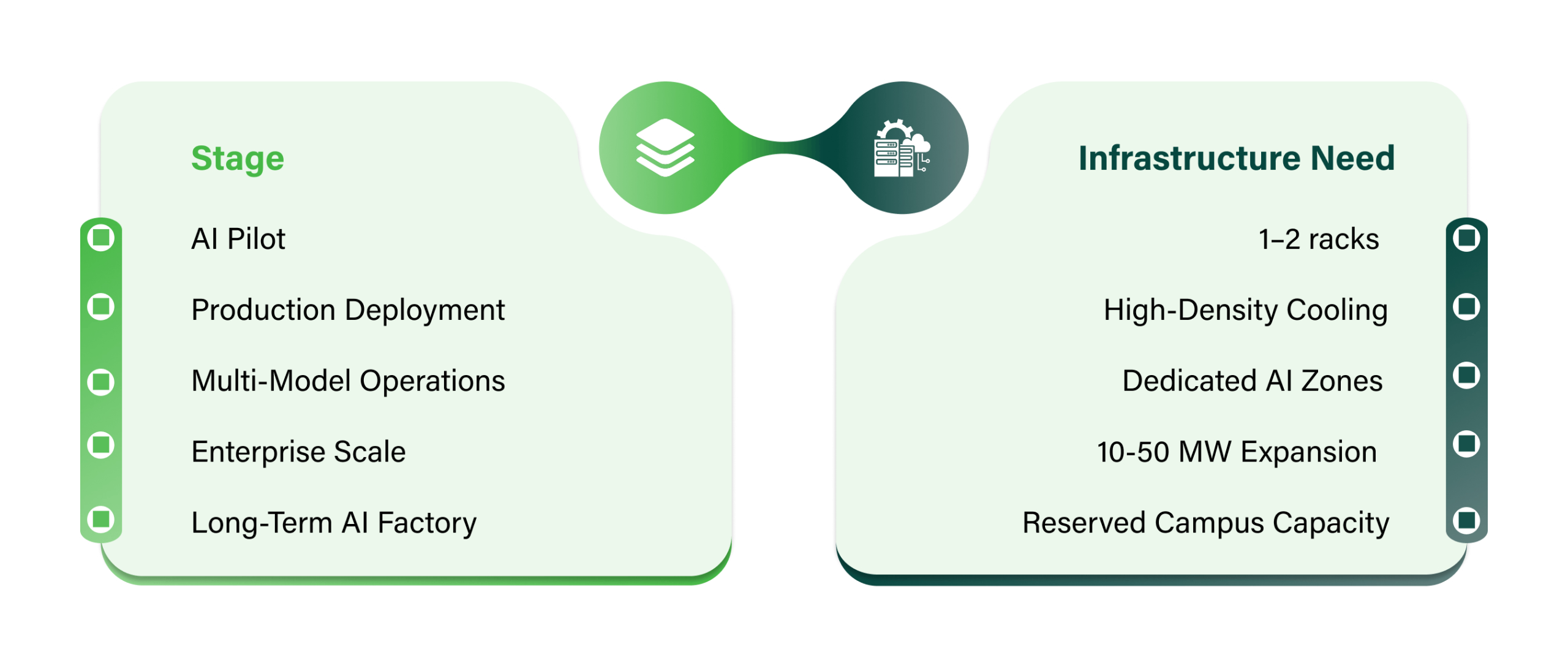
Q7: What Does Your Capacity Roadmap Look Like Over the Next 3–5 Years?
AI infrastructure demands compound quickly. Enterprises that start with a 5 MW deployment frequently find themselves planning for 50 MW within two to three years as workloads prove out and production deployments scale.
A provider whose current capacity fits your immediate requirement but has no committed expansion pipeline will become a constraint at precisely the moment your infrastructure needs to move fast.
The questions to ask are about commitment.
- Is the MW expansion pipeline funded and underway, or aspirational?
- Are campuses shovel-ready or still in design?
Hyperscaler co-deployments are a useful signal here; they indicate that a provider’s infrastructure has been stress-tested against the most demanding customers in the market.
Also confirm the commercial model: whether reserved capacity, build-to-suit, or phased expansion rights are available, and whether you can grow without renegotiating your original terms.
Ask to see the campus site plan, and confirm whether it includes dedicated enterprise zones with reserved expansion rights before demand forces the conversation.
The AI Datacenter Scale Timeline
Why CtrlS Is Built to Answer Every Question on This List
These seven questions were not designed with any single provider in mind, but CtrlS was built to answer all of them.
Across power, cooling, resilience, compliance, sustainability, speed, and scale, every criterion maps directly to infrastructure that is operational today or contractually committed.
- Power: Purpose-built for high-density GPU workloads, with transformer and UPS-level redundancy at the rack level, not averaged across the facility.
- Cooling: Air, direct liquid, and immersion cooling are all live. Design PUE targets as low as 1.2, with 40% lower energy costs compared to conventional cooling architectures.
- Uptime: Asia’s largest Rated-4 datacenter operator, with a 99.995% uptime SLA, military-grade 9-zone physical security, and 18+ years of operational track record behind that number.
- Sovereignty: 19 facilities across 9 Indian cities, no offshore routing at any layer, and active deployments with 60 Fortune 500 companies, 17 of India’s top 20 public sector banks, and SEBI-regulated institutions.
- Renewables: GreenVolt captive solar with 50 MW live and 50 MW under execution, a strategic partnership with NTPC Green Energy targeting 2 GW of renewable capacity, and a committed path to 100% renewable energy by 2030.
- Speed: 25% faster build than market average, with full backward integration across design, engineering, construction, and operations, land-to-live under a single ownership chain.
- Scale: 370 MW operational today, with a funded roadmap to 2 GW by 2030 across shovel-ready campuses in Mumbai, Hyderabad Chandanvelly, and Pharma City, validated by the trust of 5 of the world’s top 7 hyperscalers.
Conclusion
Most providers can answer these seven questions on a slide deck. Fewer will put the answers in a contract. Almost none will back them up with a site visit, operational incident logs, and certifications that hold up under a regulator’s review.
Enterprises scaling AI workloads in India need a partner with live capacity, funded expansion pipelines, and a compliance posture that has already survived the audits their industry demands. The bar is not a provider building toward these capabilities, it is a provider that has already crossed them.
Talk to a CtrlS infrastructure specialist and bring these seven questions with you.
Frequently Asked Questions
What does “AI-ready datacenter” actually mean, is there an industry standard?
There is no universal standard. In practice, it means the facility supports high-density rack power of 50 kW and above, advanced cooling, low-latency connectivity, and operational controls suited to continuous AI training and inference workloads.
What is the difference between Tier IV and Rated-4 certification?
Both denote concurrent maintainability and fault tolerance, but Rated-4 requires operational verification in addition to design certification, making it a higher evidence bar than Tier IV design compliance alone.
How does data sovereignty affect AI workload placement for Indian enterprises?
India’s DPDP Act and RBI and SEBI IT guidelines restrict cross-border data processing for sensitive categories. AI training on regulated data must occur within Indian facilities under auditable infrastructure controls.
Should enterprises prefer colocation or build-to-suit for AI infrastructure?
Colocation suits enterprises that need immediate capacity with room to scale incrementally. Build-to-suit is the right model for organisations with long-horizon, GW-scale requirements that demand custom power and cooling architecture from day one.
How long does it realistically take to go from contract to live AI-ready capacity in India?
Market timelines range from 18 to 36 months, depending on land, power access, and permitting. Providers that own the full build chain (land, power, design, and construction) can compress that window significantly.

Kallol Sen, EVP & Regional CEO, CtrlS Datacenters
With over 28 years of experience in IT solution sales and business growth across government, manufacturing, energy and utilities, banking, and financial services sector, Kallol has successfully led growth strategies across accounts, territories, verticals, and channel ecosystems, driving sustained business expansion and customer engagement. Kallol brings extensive expertise in system integration services, business development, account management, alliances, and channel performance. With end-to-end experience spanning consulting to implementation, he is known for building strong client relationships, delivering enterprise solutions through proven delivery models, and driving high-performance sales organizations.
 marketing@ctrls.in
marketing@ctrls.in