When floods swept through Chennai in 2023, major businesses faced hours of downtime. Banking systems stalled. Cloud access was cut. Hospitals struggled to retrieve patient data. Similar scenes unfolded after cyclones in Odisha and earthquakes in Japan. Each incident is a reminder of how fragile central infrastructure can be.
With climate-related disasters growing 80% over the past two decades, the cost of downtime has never been higher, reaching millions per hour for critical sectors. Traditional disaster recovery, reliant on distant backup sites, can’t respond fast enough.
In disaster-prone regions, resilience demands a new approach. Local edge datacenters, positioned close to users and operations, are redefining recovery, ensuring continuity even when the central cloud goes dark.
In this blog, we discuss everything you need to know about disaster recovery with edge data centers. Let’s dive right in!
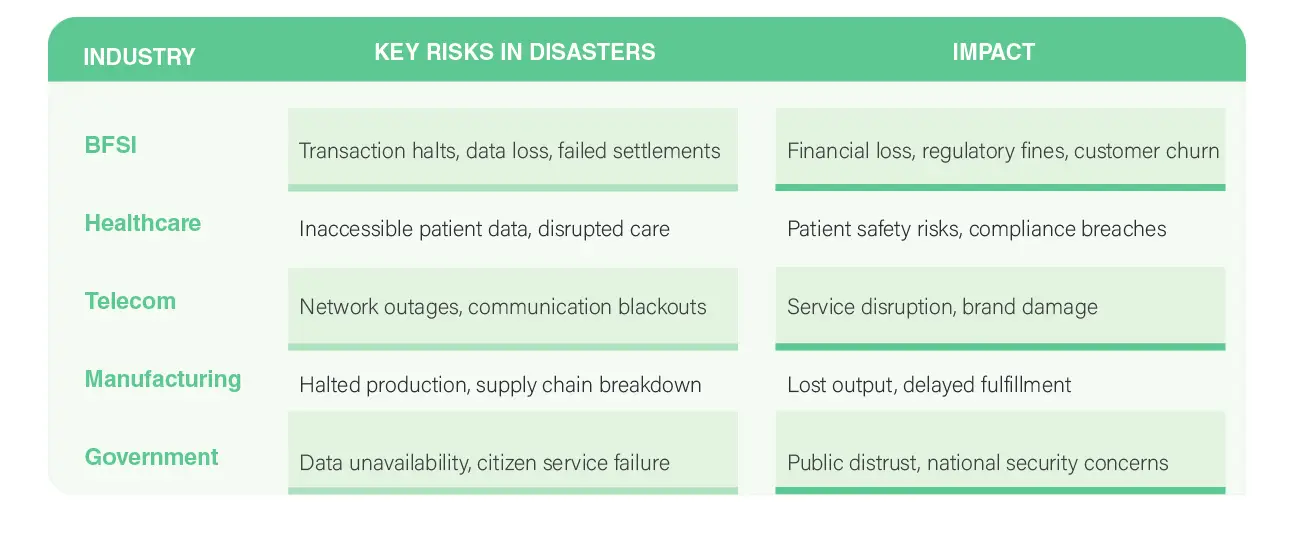
The Stakes in Disaster-Prone Regions
When a disaster strikes, the impact extends far beyond physical damage. Every minute of downtime translates into lost revenue, halted operations, and rising recovery costs.
For regulated sectors, prolonged outages can trigger compliance violations and hefty penalties. As systems remain offline, customers lose trust. And once trust erodes, reputation follows. Rebuilding credibility takes years, while competitors move in overnight.
The ripple effect is clear: operational disruption leads to financial loss, which escalates into regulatory and reputational risk, ultimately shaking customer confidence.
Why Traditional Disaster Recovery Falls Short
Conventional disaster recovery depends on centralized or distant backup sites. These are often hundreds or thousands of kilometers away. While this worked in the past, today’s real-time business demands make it insufficient.
Long distances create latency, strain bandwidth, and slow down data replication. When disasters strike entire regions, even secondary sites can be affected, leaving organizations exposed. The result: recovery times stretch, data loss grows, and resilience falters.
Key limitations are:
- High latency: Slow data transfer and delayed synchronization.
- Bandwidth bottlenecks: Limited throughput during large-scale recovery.
- Single points of failure: Remote DR sites are vulnerable to regional events.
- Weak RTO/RPO compliance: Recovery time and data loss objectives are often missed.
- Operational inefficiency: Complex failover processes delay full restoration.
What “Disaster Recovery at the Edge” Means
Disaster Recovery at the Edge brings backup and recovery closer to where data is generated and used. Instead of depending solely on distant cloud or central datacenters, organizations deploy local or micro-datacenters that act as nearby recovery nodes. These edge sites enable instant failover, faster data access, and continued operations, even when regional networks go down.
Think of a hospital in a coastal city: when a cyclone cuts off cloud connectivity, its local edge datacenter keeps patient records accessible and critical systems running. Edge DR doesn’t replace cloud recovery; it complements it. How? By creating a multi-layered safety net that ensures business continuity from the ground up.
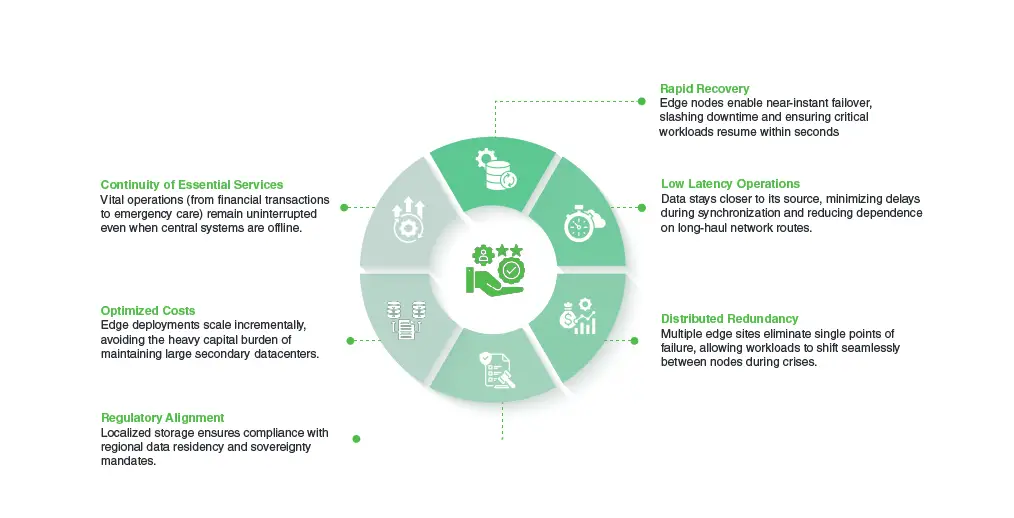
Benefits & Advantages of Edge-Based DR
Edge-based disaster recovery transforms resilience from a reactive measure into a built-in capability. By distributing recovery infrastructure closer to users and operations, organizations gain both agility and assurance.
Challenges and Strategic Considerations in Deploying Edge-Based Disaster Recovery
If you’re implementing disaster recovery at the edge, you’ll have to rethink infrastructure and architecture. The move from centralized recovery to distributed resilience introduces new variables in design, deployment, and ongoing management.
To unlock the full potential of edge DR, leaders must balance performance gains with operational realities.
1. Precision in Site Selection
Choosing the right edge locations is critical. Factors like power availability, network connectivity, and proximity to hazard zones directly influence resilience. An edge site in a floodplain or power-unstable region can undermine the entire recovery strategy. Site selection must be data-driven, factoring in latency maps, grid reliability, and regional risk profiles.
2. Operational Complexity at Scale
Unlike traditional DR, edge-based setups involve managing multiple distributed nodes, each with its own hardware, network, and local dependencies. Maintaining consistency across these environments demands automated monitoring, unified dashboards, and strong configuration governance to prevent drift or downtime.
3. Orchestration and Data Synchronization
Coordinating recovery workflows across diverse edge locations is a technical challenge. Seamless replication requires low-latency interconnects and intelligent routing to avoid data divergence. Many enterprises are now adopting containerized workloads and edge orchestration frameworks to enable synchronized recovery and workload mobility.
4. Testing, Validation, and Audit Readiness
Disaster recovery plans are only as strong as their last test. Edge DR environments require continuous simulation, not annual drills. Automated failover tests, backup verification, and performance benchmarking are essential to ensure readiness under real-world stress conditions. This rigor also supports compliance audits and reassures regulators of operational continuity.
5. Security and Access Governance
More edge sites mean a larger attack surface. Each node must have zero-trust access controls, local encryption, and monitored endpoints. Integrating identity management across distributed recovery sites is crucial to maintaining both resilience and compliance.
Building an Edge-Based Disaster Recovery Roadmap: Best Practices for Execution
Successful edge-based disaster recovery is built through precision planning, disciplined testing, and continuous alignment between IT and business objectives. CIOs and CTOs must approach implementation as a phased transformation, not a one-time deployment. The roadmap below outlines a structured approach that balances speed, control, and scalability.
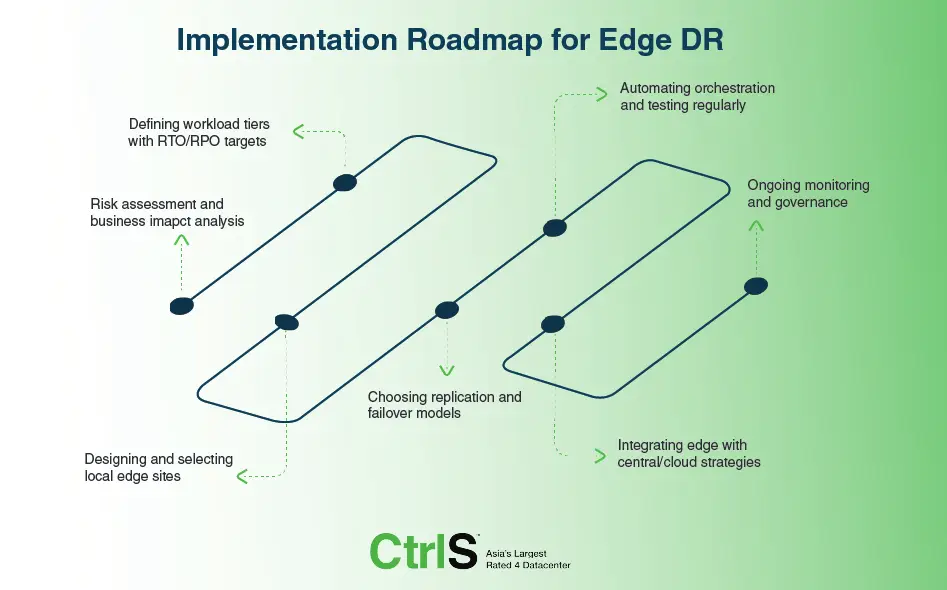
- Risk Assessment & Business Impact Analysis (BIA): Identify mission-critical processes, data dependencies, and the financial cost of downtime. Establish recovery priorities based on impact severity.
- Define Workload Tiers & RTO/RPO Targets: Categorize applications by criticality and assign measurable recovery time and data loss objectives for each.
- Design & Select Edge Sites: Evaluate locations for network proximity, power reliability, physical security, and regional risk diversification.
- Choose Replication & Failover Models: Implement synchronous replication for critical workloads and asynchronous for less-sensitive operations. Select active-active or warm standby architectures based on business need.
- Automate Orchestration & Testing: Use infrastructure-as-code, continuous validation, and automated failover drills to ensure readiness.
- Integrate Edge with Cloud & Core: Maintain interoperability between local, cloud, and central systems through hybrid networking, unified authentication, and consistent configuration management.
- Continuous Monitoring & Governance: Track SLAs, conduct periodic audits, and evolve recovery strategies with performance insights and compliance updates.
Edge + Cloud: The Balanced Path to Modern Disaster Recovery
Edge-based disaster recovery doesn’t replace the cloud at all. If anything, it strengthens it. The most resilient organizations are adopting hybrid DR architectures, where edge nodes handle immediate failover and continuity, while central or cloud environments manage heavy compute, analytics, and long-term data retention. This layered approach ensures real-time responsiveness at the edge and scalable protection in the cloud – the best of both worlds.
Leaders like CtrlS are enabling this hybrid model with enterprise-grade Disaster Recovery Services backed by penalty-based SLAs, 24×7 monitoring, and multi-platform compatibility. Whether it’s a hot edge site with RPO <15 minutes or a cloud-based warm standby, CtrlS ensures guaranteed recovery across infrastructure and applications.
With advanced DR workflow management, real-time dashboards, and expert consulting, CtrlS helps enterprises design hybrid DR frameworks that deliver faster recovery, stronger compliance, and uninterrupted business continuity even in the most disaster-prone regions.
Measuring Success: KPIs, Metrics & ROI
To justify investments in edge-based disaster recovery, organizations must track measurable outcomes that bridge technology performance and business impact. These metrics demonstrate how resilience translates into financial and operational value over time. Monitoring them helps CIOs validate strategy, optimize spend, and sustain executive buy-in.

Disasters are inevitable, but downtime doesn’t have to be. In an era of climate volatility and digital dependence, edge datacenters transform disaster recovery from a fallback plan into a proactive resilience strategy. By combining edge agility with cloud scalability, enterprises can ensure business continuity even when the unexpected strikes.
Ready to strengthen your organization’s disaster resilience? Connect with our experts for a personalized Edge DR Strategy Session designed to secure your operations, wherever disruption occurs.

Vipul Kumar, Senior Vice President – Edge & Network Business, CtrlS Datacenters
Vipul is a seasoned telecom and datacenter leader with over two decades of rich experience spanning submarine cable systems, edge datacenters, and network infrastructure ecosystems. He is passionate about building sustainable, compliant, and scalable digital infrastructure that empowers regional enterprises, SMEs, and hyperscale players alike. As Senior Vice President – Edge & Network Business at CtrlS, he leads initiatives that bridge connectivity and compute — from fiber and network deployments to strategic partnerships and business development, building the network foundation and ecosystem partnerships that power CtrlS’s pan-India edge datacenter expansion.
 marketing@ctrls.in
marketing@ctrls.in